Using wrong MIME type in images to serve HTML
Abstract: An attacker uploads an image to a trusted website which contains HTML and Javascript, but tricks the website to serve the image as an HTML document.
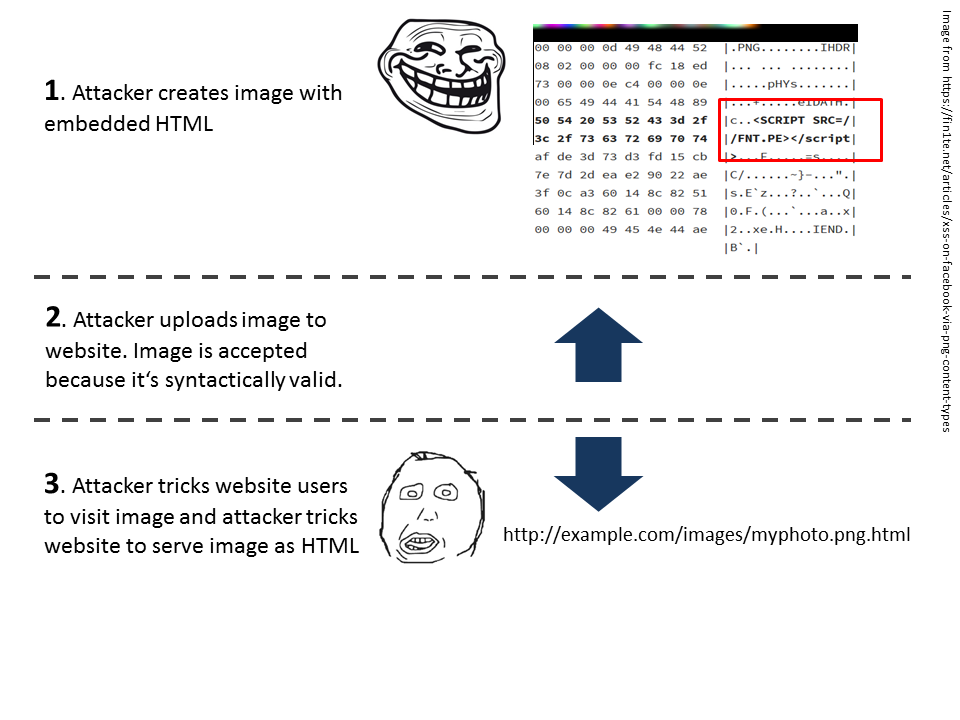 |
| Overview of the MIME-type attack |
Stealing secrets with user-contributed CSS

0) Attacker must somehow be able to inject CSS into the compromised website (e.g. user-styled blog or forum).
Stealing web page content by tricking the browser to load the private page as CSS
Abstract: An evil website steals content from a trusted web page the user is logged into by tricking the browser to load the trusted web page as CSS. Requires that the attacker can inject a bit of text into the trusted website.
This one is a bit older and is possible because of lenient CSS parsing [6] and the fact that Javascript is allowed to look into CSS declarations. I’m not sure to what extent this is countered browsers, I read conflicting statements about that on the interwebs. The exploit requires:
1) a victim Victor
2) a website Webmail to which Victor is logged in which contains some private content. Webmail doesn’t have to be open in a tab or window, as long as the user is authenticated and logged into Webmail via a session cookie.
3) a website example.com which the attacker controls
4) Victor visits example.com
5) The attacker must be able to inject some text into Webmail (e.g. by sending Victor some emails he can read in his Webmail)
The exploit works like this:
1) Victor visits our malicious website example.com
2) example.com contains a link HTML element which tries to load an external CSS style sheet. Only, instead of referencing a valid style sheet, it references a page that is Victor’s inbox on Webmail. This will cause the browser to load the forum HTML as a CSS and parse it. Not much harm so far.
3) The attacker is able to inject some text into Webmail that starts a CSS declaration before some sensitive text and end the CSS declaration after the sensitive text. An example would be if we sent Victor a message at an early date with a subject: };.emailList{ and a message at a later date with the subject };. Now, everything in the inbox overview between the first and second email we sent can be interpreted as a CSS declaration.
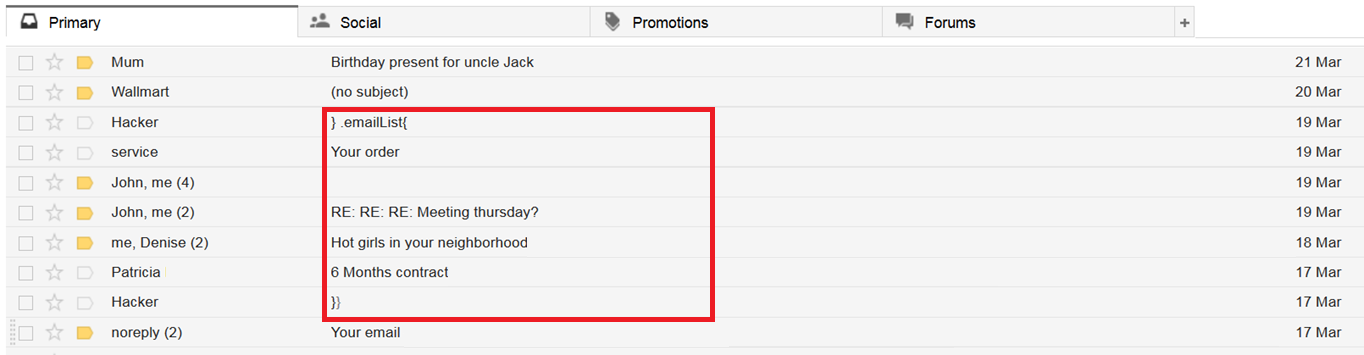 |
| Example of a compromised webmail inbox |
4) When step (2) loads that CSS, because of the CSS parser’s leniency, the browser will still be able to interpret the entire inbox as CSS, which will lead to (at least) the declaration of the .emailList class.
5) Since the attacker controls example.com he can place Javascript there that reads the cssText [8] property of the .emailList class and sends it to his server.
I remember reading about this exploit which keeps popping up over the years, but I can’t find any illustrative references any more. The articles showed how attackers are able to read a victim’s webmail inbox by sending him two emails that contained CSS declarations in their subjects. Once the attackers lured their victim to their malicious website, the attackers were able to read the victim’s inboxes as CSS declarations.
Angular injection
In case you wonder why any sane web application would perform server-side rendering of user-submitted content (step 2): SEO or fallback strategies for feature-reduced clients are frequent use cases.
HTTP injection
This type of attack also called HTTP protocol nesting or HTTP request smuggling [10] exploits weaknesses in HTTP protocol implementations of the participating devices.
The paper’s authors discuss several real-world examples targeted against eponymous server software which lead to exploits like cache poisoning [11] or credentials hijacking. The exploits mostly involve a cascade of server software like a reverse HTTP proxy and a web server. An example:
Cache poisoning: a malicious client sends a nested request to a reverse web proxy with a web server behind it. The proxy parses the faulty request in a way that it thinks a URL U1 is requested, while the web server parses the request in a different way and things that URL U2 is requested. The web server then return the contents of U2, but the proxy stores that content under the URL U1. Hence, any further legitimate requests for U1 will serve the content of U2. The exploit works, oversimplified, like this:
POST U1
Content-Length: 0
Content-Length: 123
GET U2
….
Because of the conflicting Content-Length statements, the web proxy may consider the POST content to start at a different point than the web server behind it, so the web server may serve U2 but the proxy may store U2’s contents under U1.
The authors discuss more vulnerabilities; a worthwhile read in any case!
Finding out which sites a user visited
A malicious webpage could find out in older versions of popular browsers which websites a user visited, fortunately that doesn’t seem to be possible any more [12]. The “exploit” is simple and effective: the malicous webpage generates a list of links it is interested in. If the user has visited any of those in the past, the browser will render them in a different style. The webpage can query that style via a script and send the results away. Browsers have stuffed that hole with a combination of reporting fake values to scripts and limiting the amount of styling (e.g. you can’t change any dimensions of the visited link, so querying container sizes won’t work).
[16.04.2016]
Abusing URL indexing to scan for private data
From here [13]: Let’s say a website exposes some content under an unguessable URL, e.g. by including an UUID like Google+ does for sharing private content with a private link, like example.com/sdflo234ngnofgo23onigu. Only people who know that URL can access that page, the access is supposed to be secure because “sdflo234ngnofgo23onigu” is very hard to guess. An attacker couldn’t possibly afford to check all possible character combinations that result in URLs to example.com and it is kind of understood and implied that nobody would publish that URL on the web, otherwise it would be indexed by search engines and could be discovered there.
However, if you pass the URL through an URL shortener, the search space is decreased dramatically: example.com/sdflo234ngnofgo23onigu would become ex.co/BlD33_. An attacker can easily afford to scan the much fewer URLs on a shortening service and discover (private) URLs submitted to that shortener.
[31.07.2016]
Allowing clients to pick protocols
I couldn’t come up with a better title that succinctly describes the problem: the server sends data which is encoded/secured/signed in a way which guarantees its sanctity, but the client is allowed to send said data back to the server or another server with a different, less secure protocol.
The idea came from a security vulnerability [14] recently found in multiple JSON web token implementations. JSON web tokens implement digital signatures that verify data’s authenticity and integrity, so that when a client gets data from a service A and passes it to a service B, that service B can verify the data’s integrity based on the the JSON web token without communicating directly with service A. In this vulnerability it was possible for clients to request a protocol implementation which bypasses verification per design. The lesson learned here is: parties involved in a communication who delegate security aspects to an underlying implementation should verify that the implementation works.
The issue of not validating security assumptions comes up frequently, e.g. in 2014 CERT found out that several Android apps were not validating server certificates [15].
[31.08.2016]
Phishing with target=_blank links
You knew that an HTML anchor link with target=”_blank” opens the linked page in a new tab or window. But did you knew about the window.opener [17] Javascript property? The new window can access the old window through that property; thankfully, most (sub) properties of window.opener aren’t readable by the new window, but the window.opener.location property can be changed which makes it practical for phishing attacks: you click on a link in your webmailer, it opens a new page and in the background just redirected the window which had the webmailer open to an identically looking login page on a similar domain, telling you that your session expired and asking you to log in again. Discussed on the Founders Blog [16]. The solution is, where supported, to add a rel="noopener" tag or not use targets at all.
[24.10.2016]
Breaking out of a sandbox with Rowhammer.js
The Rowhammer [18] attack exploits weaknesses in current DRAM implementations at the hardware level where specially constructed write patterns can interfere with the content of unrelated memory locations. Rowhammer.js [19], a Javascript implementation, surfaced (not so) recently which ports Rowhammer to the browser. While I see Rowhammer as a hardware exploit, I’m still mentioning the exploit for its novel approach.
[09.01.2017]
Phishing autofilled fields
Sneaking past validation with XML comments
A rather specific SAML exploit [21] can be generalised to XML parsing. The underlying idea is that XML is used as a data container format, but the programme which parses XML and processes the data often isn’t aware of XML format subtleties which can lead to ambiguities. The attack in focus plays on the ambiguity of XML comments:
<name>John<!--comment-->Doe</name>
Conceptually speaking, what is the text value of the “name” element? From a w3c perspective, the “name” element has three children: a text node with the value “John”, a comment node with the value “comment” and another text node with the value “Doe”.
The SDKs and frameworks of many programming languages offer convenience functions for getting XML node text values. Depending on their implementation, the values “John Doe”, “JohnDoe”, “John” or “Doe” might be returned. Most programmes will probably use such convenience functions, but as modern systems consist of several data processing layers (HTTP, WAF, validation frameworks, web application frameworks) each such layer might use a different “convenience” implementation. This attack reminds me a bit of “HTTP injection” we’ve seen earlier.
Clickjacking social media login widgets
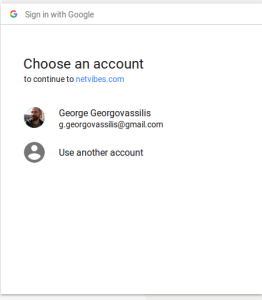
[update 2018.05.10] The Google YOLO exploit [22] falls into a broad category of clickjacking attacks on a user’s social network account. You probably know the “sign in with Facebook” feature which allows a web site to identify a user by his social network account. The premise is that the user verifies the URL displayed in the browser’s address bar, checks the type of access the website is requesting and can grant (or not) that access.
This exploit:
- consists of a malicious web page
- embeds the social network login page in an iframe
- places another HTML element over the iframe, obscuring it OR
- places the login iframe over the webpage but making it invisible
- uses the CSS pointer-events and opacity properties to direct clicks intended for the website to the social login button
Websockets to localhost
[Update 22.05.2020] Major browsers will allow any site to open websockets from the browser to their domain… and localhost. There is demo of an exploit [23] which connects to TCP ports on the computer running the browsers and searching for stuff. Thus it is possible for malicious websites to connect to local databases and proxies.
Resources
http://blog.portswigger.net/2016/01/xss-without-html-client-side-template.html
[8] cssText Web API MDN
https://developer.mozilla.org/en-US/docs/Web/API/CSSRule/cssText
[9] AngularJS
https://angularjs.org/
[10] HTTP Request Smuggling
http://www.cgisecurity.com/lib/HTTP-Request-Smuggling.pdf
[11] Cache poisoning
https://www.owasp.org/index.php/Cache_Poisoning
[12] Privacy and the :visited selector
https://developer.mozilla.org/en-US/docs/Web/CSS/Privacy_and_the_:visited_selector
[13] Gone In Six Characters: Short URLs Considered Harmful for Cloud Services
https://freedom-to-tinker.com/blog/vitaly/gone-in-six-characters-short-urls-considered-harmful-for-cloud-services/
http://securityaffairs.co/wordpress/28151/hacking/cert-test-android-apps.html
[16] The target=_blank attack
https://medium.com/@jitbit/target-blank-the-most-underestimated-vulnerability-ever-96e328301f4c#.j0dxr7gn3
[17] window.opener
https://developer.mozilla.org/en/docs/Web/API/Window/opener
[18] Rowhammer
https://googleprojectzero.blogspot.de/2015/03/exploiting-dram-rowhammer-bug-to-gain.html
[19] Rowhammer.js
https://arxiv.org/abs/1507.06955
[20] Browser autofill phishing
https://github.com/anttiviljami/browser-autofill-phishing
[21] A breakdown of the new SAML authentication bypass vulnerability
https://developer.okta.com/blog/2018/02/27/a-breakdown-of-the-new-saml-authentication-bypass-vulnerability
[22] Google YOLO
https://blog.innerht.ml/google-yolo/
[23] Stealing Secrets from Developers using Websockets
View at Medium.com

Update on abusing URL shorteners to discover private content
LikeLike
Update about skipping validation with JSON web tokens
LikeLike
Update about social network clickjacking
LikeLike