What is the right code granularity?
I have previously written about reusing functionality [1] in the micro service context and found then that the old aim to optimise code footprint is a metric in need of a good overhaul. Ever since I’m happy that the idea is getting traction:

Classes, libraries, applications
OOP reuses code and functionality on the conceptual level through polymorphism [2] and inheritance where functionality is tagged with interfaces and placed into a class hierarchy. The granularity of code reuse in OOP is a method contributed by a class. [My unrelated objection is that while OOP pretends class inheritance to be an ontological concept (eg. a Fiat is a Car), the technical reality of compilers and programming languages is that any appearance of a semantic class hierarchy is an illusion [3] tattered by sub-classing just importing code from super-classes.]
From a deployment/packaging point of view, code is organised into libraries such as DLLs or JAR files, which add some tangibility and governance to the purely conceptual organisation of functionality into classes: versioning, artefact origin and ownership, code size, packaging, package composition, deploy-ability.
At run-time, application module communication happens through a direct function call, a decoupled messaging mechanism, a remote method call, REST services, a message queue or an ESB. The kind of communication mechanism used also defines the application deployment: are various application modules co-located in a monolith? Is the application invoking remote services over a network or is even a distributed service architecture at play?
 |
| Functionality is organised in classes, packages and services |
By looking at the software development life cycle from development to deployment to operation we’ll notice a change in granularity of function reuse: the development phase is governed by the single responsibility principle [4] which mandates that a particular functionality is located in a single class, so functional granularity equates class granularity. During deployment, code is packaged into libraries or even larger deployment artefacts such as EAR files; functional granularity now grows towards including multiple classes. Finally, applications communicate at runtime with other applications through I/O channels (such as a network) which enlarges functional granularity to encompass entire applications or even application clusters (think about fail-over or load balancing).
Even bigger: containers
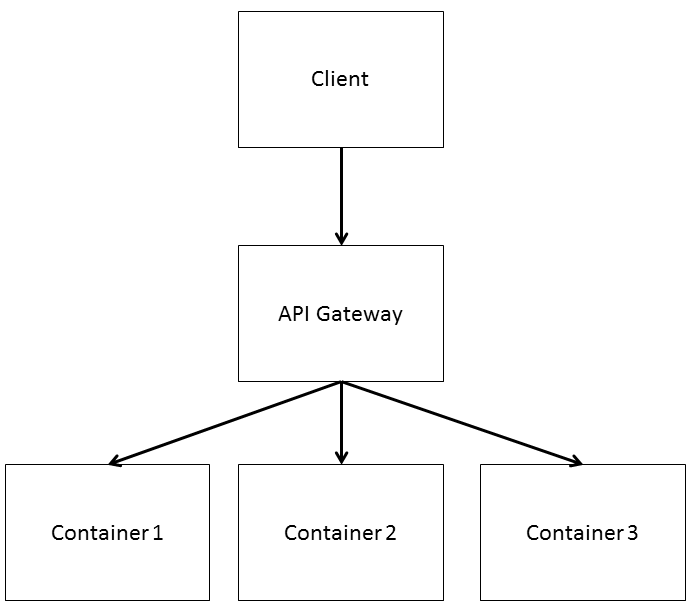 |
| Constructing applications from containers |
Docker compose [5] and AWS cloud formation [6] are two products for on-premise and cloud use, respectively, which orchestrate applications out of containers and glue them together with an API gateway [7]. The API gateway, a scaled-down concept of the ESB, routes and transforms network requests from clients to containers and similarly handles communication between containers, where necessary contributing both to container decoupling and orchestration. This container-based way of designing applications enlarges functional granularity even further: building blocks become entire collection of services which manage their own resources, persistence and communication.
The illustration below depicts a hypothetical enterprise application which delegates most of its functionality to containers of pre-packaged applications.
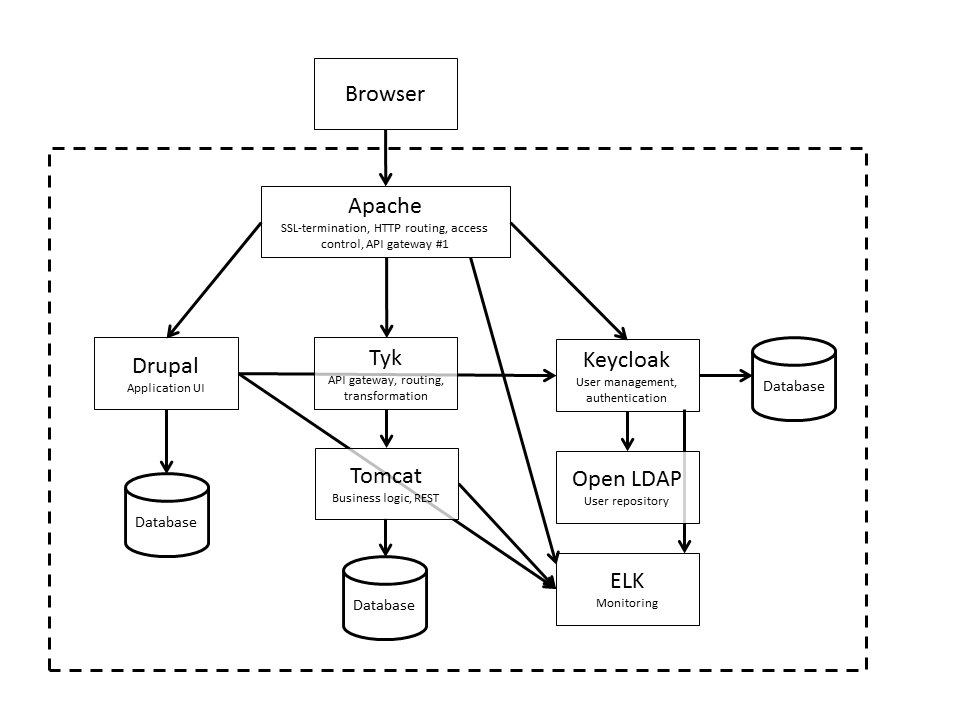
Let’s look at some functionality and the containers that implement it.
HTTP(S) traffic from web browsers is handled by a web server (Apache) which takes care of SSL termination, routes HTTP traffic to the underlying containers and restricts user access to the application by validating a cookie. The web delegates authentication and authorization to a container running a user management application.
User management, access control, authorization and authentication is implemented by a user management application (Keycloak) which runs in a container of its own and offers a single sign on service (eg. OAuth) for authenticating application users, an API which the web server connects to and a management UI over which application administrators can handle users.
User information and access credentials are stored in an LDAP registry running in a dedicated container which is connected to the user management application.
The main application logic runs in a container with an application server (e.g. Tomcat) and exposes nothing but REST services, keeping things simple.
REST requests to other parts of the application are adapted and routed internally with an API gateway (e.g. Tyk). Its job is to adapt the various APIs contributed by containers to an application-wide convention and possibly implement fine-grained access control.
A dedicated CMS container (Drupal) handles the presentation layer such as rendering the appropriate HTML for different clients or channels and serving the respective static resources such as images and Javascript libraries. It also offers a management interface for application administrators.
Last, not least, a packaged monitoring solution (here the famous ELK stack) collects logs from other containers, stores them for review and exposes a web UI for application administrators to query and monitor usage and performance.
Reflecting on container-based design
Wiring together applications from containers may look like a strange and at times wasteful idea, but it is not that much different from how applications are operated in reality already: much of the end-to-end functionality needed by a modern web offering is not implemented by the web application itself, but contributed by third-party systems: SSL termination and load balancing is done by a front-end proxy, LDAP is magically operated magically by the company’s friendly system administrator and databases have always been independent processes.
The novel approach container-based design brings to application architecture is that many runtime dependencies are not operated any more outside the application owner’s control, instead they are deployed and operated as an integral part of the application. Much functionality is contributed by application configuration rather than application development and packaged applications usually contribute much more functionality than frameworks or libraries which reduces coding effort. Robustness should, in theory, also increase as individual containers can be taken off-line, more instances can be launched and individual containers can be restarted, affecting only the functionality they contribute instead of taking the entire application off-line. Patches can be applied to individual containers requiring no application-wide downtimes.
Obvious drawbacks are a shift of responsibility from the general system administration domain towards the application owner. With great power comes great responsibility, which certainly is the case with container-based design where an application implements so much more functionality. The shift of operational responsibility also comes with a proportional shift of resource consumption since applications need to contribute at least a single container for every piece of functionality which, otherwise, might have been offered by a shared system component.
Resources
[1] The art of copy & paste – George’s Techblog
https://blog.georgovassilis.com/2016/06/the-art-of-copy-paste-in-programming.html
[2] Code polymorphism, Wikipedia
https://en.wikipedia.org/wiki/Polymorphism_(computer_science)
[3] java.util.Date cannot be cast to java.sql.Date
http://stackoverflow.com/questions/21575253/classcastexception-java-util-date-cannot-be-cast-to-java-sql-date
[4] Single responsibility principle, Wikipedia
https://en.wikipedia.org/wiki/Single_responsibility_principle
[5] Docker compose, Docker
https://docs.docker.com/compose/
[6] AWS cloud formation, Amazon
https://aws.amazon.com/cloudformation/
[7] AWS API gateway, Amazon
https://aws.amazon.com/api-gateway/

Edited for typos
LikeLike