
I love learning a term for a vague idea that has been with me for a while already; it gives the fuzzy cloud in my head a box to live in and a label to put under… not to mention convenient stowage when I need room for other things. One such illuminating moment was listening to Axel Fontaine’s “Majestic Modular Monolith” talk (a pun on the term “Majestic Monolith” coined by David Heinemeier Hansson) which discusses strategies for developing monolithic applications which remain performant and manageable.
Monoliths are often redesigned into micro service architectures (MSA) because of pain points with their current, monolithic architectures, hoping that micro services are faster, more flexible and easier to manage. The MMM takes some good concepts of micro service architectures, combines them with good craftsmanship and delivers a monolith that can be both flexible and scalable, making it fit for almost anything but the largest applications.
The most important ingredient of the MMM is the realisation that modularisation is a logical concept which does not necessarily have to be reflected at the deployment level something which I’ve explored in The are of copy & paste and Code reusability in the age of containers. For example, we can think of functionality in terms of objects and classes, even if at the end of a deployment they end up in the same binary package compiled to machine code. The MMM is built on services which are clearly defined, isolated, have concise APIs and share no logical data store. It’s essentially the discipline of micro services with the amenities of monoliths.
I’ll briefly list some of the issues of monolithic applications and solutions for them, which fall into three broad categories: availability, complexity, management. Spoiler alert: most of the solutions revolve around modularisation 🙂
Problems and solutions
Availability
Availability is anything related to an application running and serving users and includes aspects such as uptime and performance. The core arguments against monoliths are that their deployment is slow and they don’t scale.
Downtimes
Problem: since the monolith is a single process, any artefact deployments will require stopping the process, installing the artefact and restarting the process. Especially as artefacts become large (monoliths tend to do that…), these three stages take longer and longer for each deployment.
Solution: just as micro service systems achieve uptime through routing requests away from irresponsive service instances toward responsive service instances, an HTTP load balancer or an API gateway achieve a similar effect. Monolithic instances can be deployed one after the other while the load balancer directs requests only to active instances. Changes in the database schema or APIs to external services can be handled with modules which can speak both versions and feature toggles.
Slow deployments
Problem: As the monolith grows, there is more source code to compile, more dependencies to manage and download, more tests to run, larger databases to query and more bytes to move. All of that should be multiplied with the frequency of code commits which, for a large application, should also grow over time which leaves us with an O(N²) complexity.
Solution: it’s important to remember that, while modules end up in the same monolith, they are not necessarily part of the same code base. Each module can be compiled and tested independently and in parallel to other modules, keeping build and test times low. Any system- or integrations tests will, of course, have to run against the full monolith, incurring its high start time.
Small changes require full redeployments
Problem: the monolith is packaged and deployed as a single artefact (think of a WAR file) and often runs as a single process in the operating system, which requires building, deploying and running that single, large artefact with every change to the application code or configuration.
Solution: this is a compound issue of “slow deployments” and “downtime”, both of which have their respective solution.
Performance & resource consumption
Problem: large processes require considerable resources, often to just “exist” idly in memory. Their start time is considerable and they indiscriminately need to keep in memory data for their entire domain.
Solution: By having large instances, in terms of resource consumption, the monolith can obviously not compete with the resource consumption of a micro service, but one should look at the application as a whole. The monolith is the application while it takes a set of micro services to make up the application. The monolith benefits from direct in-process communication between its modules which is much faster than micro services communicating with each other over a network. A monolith may also share caches between its modules and runs in a single process instance as opposed to micro services which, if they run in containers, also might clone significant parts of the host operating system.
Scalability
Problem: a major benefit of micro service oriented architectures is their ability to scale individual services as required. A monolith, obviously, lacks this luxury; it can scale only as a whole by replicating instances of the entire application. The single database schema doesn’t scale well because of all the interconnecting constraints, joints and large tables.
Solution: as scalability is a parade discipline of MSAs it is hard for the monolith to compete with it. Running multiple monolith instances behind load balancers can, however, work well for many work loads and domains considering that the tight packaging of modules leads to a higher baseline performance per service instance. Just as MSAs achieve scalability through denormalisation which removes dependencies between entities by duplicating data into isolated data stores, the monolith can (and should) do the same: different modules access different database tables (or even schemata) with synchronisation happening comfortably under the protective umbrella of database transactions.
Robustness
Problem: An MSA survives service failures by routing requests away from inoperative service instances, eventually gracefully degrading functionality if no instances of a particular service are available. A service that is not available does not render the entire system unusable but simply disables the affected functionality. A monolith, on the other hand, might even fail to start if one component runs into an error.
Solution: caching of stale content until components are back on line, having a load balancer route requests to operative instances and circuit breaker implementations like Hystrix approximate some of the benefits of MSAs without the perils of unreliable network communication between services.
Complexity
While complexity is a broad term, I use it in relation to everything that makes understanding and programming an application harder for people. Examples include components interfering (un)expectedly with each other, lengthy code sections and incompatible dependencies.
High code complexity
Problem: I’m looking at the monolith’s code base, its hundreds of dependencies and probably as many plugins for building and running tests, linting and producing quality metrics and wondering how I’ll ever understand all of this. The database schema is vast with tables referencing each other and it’s unclear which parts send which data to the browser.
Solution: the key to managing complexity is, again, modularisation. Build tools like Maven standardise and modularise the build- and deployment process of software projects. Code can be functionally grouped into isolated modules that have their own build process, making programming with individual modules easy and concise.
Low code isolation / high interference
Problem: since the monolith makes it easy for a component to use not only the API of another component, but for the lack thereof its internal data structures or protected functions, the always-under-pressure programmer is going to do exactly that, leading to tightly coupled components and unintended interference between them.
Solution: modularising code, which is the solution to “high code complexity”, is going to help us out once more. Much of the isolation is achieved simply by packaging code into modules which forces the programmer to think about which parts of the code belong in the module’s public contract (API) and which parts are implementation-specific and thus private.
Refactoring is hard
Problem: every now and then the application requires a larger structural change to its components, APIs and data structures. All those tightly coupled components hinder refactoring with their direct dependencies and implicit dependencies (through, e.g. private data structures or shared database tables).
Solution: this might seem like a problem until you’ve tried to refactor a distributed system where you realise you’ve forgotten to rename a field only at run time. Once more, modularisation leads to clear API contracts which add the benefits of compile-time checks and IDE-assisted refactoring.
Dependency conflicts
Problem: components may require versions of libraries which are incompatible with each other. Think of DLL hell. Since all libraries end up in the same deployment artefact, a version conflict will at best lead to a compile error and at worst to a non-deterministic runtime behaviour.
Solution: this is probably the hardest problem to solve for a monolith. MSAs famously avoid this problem through APIs that consume only serialised data formats, so each service has its own, isolated, set of dependencies. Some platforms offer in-process modularisation (e.g recently Java modules) which come with their own complexity and limitations. The other solution would involve containers (see later).
Management
The meta-level of management is where product owners and architects strategically think about application development and operation. It includes concerns such as cost of ownership, time to market and architecture evolution.
Concurrent development is hard
Problem: the issues of high complexity and low component isolation discussed earlier place a limit on how many people can change code at the same time as changes may propagate in- or unintentionally to other components.
Solution: again, modularisation allows teams to work on individual modules, even multiple teams at different modules as long as they follow an API management process which negotiates and documents the contracts between those modules. MSAs sometimes run into trouble because the people responsible for service definitions don’t talk to each other, leading to incompatible APIs.
Limit on team size
Problem: this kind of goes hand in hand with the concurrent development issues. The only good use for a large team is maintaining high utilisation if members can work at the same time on different components.
Solution: the solution is the same as to concurrent development. Properly modularised components stored in separate code projects ensure a sufficient degree of isolation which allows teams to work on those modules independently.
Small choice in platforms
Problem: I listed the constraint on programming languages, frameworks and platforms as a management issue rather than a complexity issue because it limits the choices in staffing a project and imposes architectural discipline by limiting technical choices. An MSA connects services through remote APIs which can be language- and framework-agnostic (e.g. web services) allowing heterogeneous teams to deploy services in different languages on different operating platforms as long as they are connected over a network.
Solution: the restriction on platform choices goes hand in hand with “dependency conflicts” and is a result of the operational limitation of all modules run in a single process. Some, cumbersome, solutions involve emulators (e.g. running Javascript in a Java emulator) or transpilers which allow writing software in one language but executing it on the platform of another language. Other solutions involve containers (see later).
Time to market
Problem: the restrictions on team size, high code complexity and slow deployments limit the speed at which functions can be conceived, implemented, tested and rolled out to production.
Solution: as time to market is a composite problem, it can be solved by tackling its constituents: reducing complexity and speeding up deployments through modularisation.
Cost of ownership
Problem: it should be obvious that the friction and loss of efficiency introduced by the monolith’s complexity can not possibly be a money saver. Also, lower performance of monoliths increases operating costs.
Solution: in addition to the benefits of reduced code complexity and easier deployment, an MMM might reduce operating costs through an overall lower memory and network footprint.
Containers
No technical treatise in the age of cloud should go without mentioning containers. We can relax the constraint of single-process monoliths and still consider a set of containers running on the same computer as a valid monolith. In the case of single-machine container co-location, one can reasonably ignore the perils of network failures between containers, largely remaining with the comfortable monolithic programming paradigm.
Containers offer new solutions to some of the problems discussed earlier because they increase isolation between modules while increasing the choice of platforms that run in a container. However, this may necessitate that containers communicate between each other over a virtual network interface – but that might not always be the case, e.g. web applications segmenting functionality into isolated REST services.
Dependency conflicts: modules with conflicting dependencies can be deployed in different containers.
Small choice in platforms: while containers are limited by the hosting container platform in the variety of platforms they are able to run, they are a large improvement over the single-platform architecture a monolith requires.
Complexity: containers excellently tackle the broad range of complexity issues discussed earlier, for the architectural modularisation and operational isolation they offer are exceeded only by virtual machines or separate servers.
Slow deployments: since it is possible to deploy individual containers instead of the entire application, deployments are now faster and down times are reduced.
A word of caution: building with containers decisively shifts a monolith’s architecture towards MSA which may come with its own burdens like managing communication, service discovery and loss of database transactions.
Baking a majestic modular monolith
There is not much I can add here which hasn’t been said by Axel. I’d summarize it as “merging the monolith’s amenities with MSA discipline”.
Modularization and isolation
The concepts of isolation and modularisation are in equal parts complementary as they are opposite. For them to work, architects need a clear vision of how to map functionality into technical components. Modules should communicate over clearly defined APIs and take no short cuts: no direct invocations or database communication. A minimum level of isolation should be set of API modules with no implementations which is the only point of contact between modules. This makes sure that modules depending on those APIs (either as consumers or producers) don’t inherit the API implementations’ dependencies.
Larger monolithic designs might promote module orchestration and configuration into distinct modules, e.g. by using an in-process message queue or API gateway for service discovery and communication.
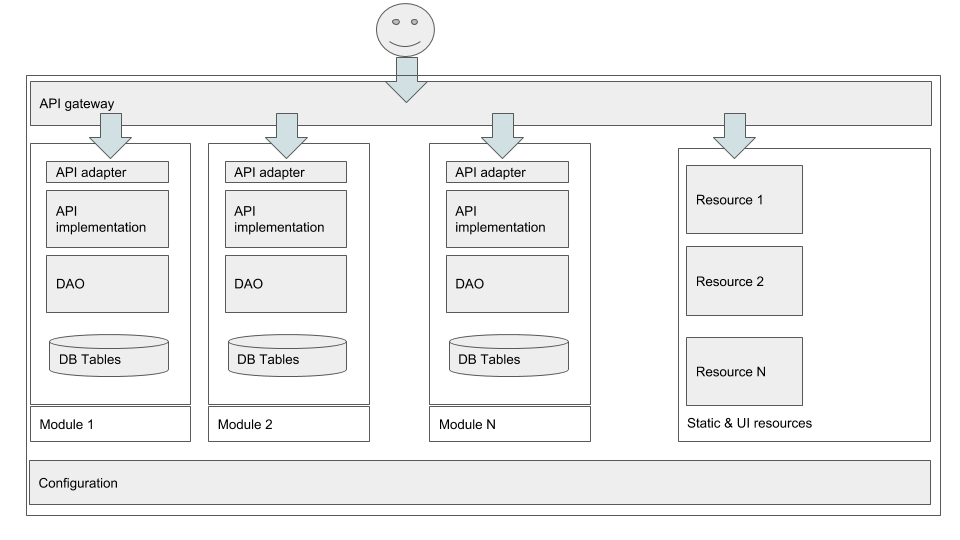
Persistence
Modules requiring persistence should access the same database for the benefit of ACID without sharing entities. Modules accessing the same tables (SQL) or document entities (NoSQL) are not truly isolated and share an implicit dependency not necessarily visible at the API level. Modules which strictly separate data access might require the overhead of denormalisation, which however leads to increased decoupling, performance and readies the architecture for a possible MSA transition.
Performance and scaling
As discussed earlier, multiple monolith instances can be run behind a load balancer. This requires, however, that components are either stateless (which is a useful goal anyway) or share state through, e.g., shared caches. On the instance level, thread pools, reactive APIs, batch- and asynchronous processing can lead to easy performance gains.
Availability and robustness
Designing for failure cases is a conscious architectural decision. Design patterns like circuit breaker, their assorted implementations like Hystrix, serving data from stale caches, gracefully degrading functionality and re-routing traffic to operational monolith instances significantly increase a monolith’s uptime.
