TL;DR: moving to the public cloud consolidates many small risks into few large ones.
A recent GCP cloud outage (https://status.cloud.google.com/incident/cloud-networking/20004) highlights an issue with running more and more parts of the internet on the same infrastructure: as more computing resources consolidate in large cloud providers’ data centres, the risk of a significant, global outage of the internet increases. In the particular case the outage affected services accessing other services running on 3rd party cloud providers and thus is a typical “weakest link in the chain” scenario.
The common argument around availability for moving to the cloud is added scalability, elasticity and resilience for a single service. From a human user’s point of view who interacts with a plethora of services on their stationary or mobile clients and the internet a large portion of the internet suddenly goes offline when a major cloud provider is experiencing hiccups.
The shift to the cloud is about shaping the risk spectrum. Clouds reduce the likelihood of a large number of small outages. The consolidation of important services on few centralised infrastructures increases the chance of large outages as described here. In case of a major cloud outage users cannot:
- use a service they are paying for (your application)
- request help (their email provider and your chat system are offline)
- get help (your CI/CD is offline)
- work around the outage (alternatives are offline, too)

The incident spectrum
The incident spectrum when moving from a decentralised, self-managed infrastructure to a consolidated cloud infrastructure also changes significantly; the graph below is an approximation of infrastructure-related production incidents between 2014 and 2015 of a system I was working on which migrated from a self-managed infrastructure to the public cloud. The x-axis is the number of incidents in a year and the y-axis is the (subjective) severity rating: everything below 0,3 affects only developers and operations personnel. 0,3 to 0,6 was (potentially) noticeable by users but didn’t result in a complaint, 0,6 and above was observed by users and everything above 0,8 had business impact (loss of revenue and reputation etc).
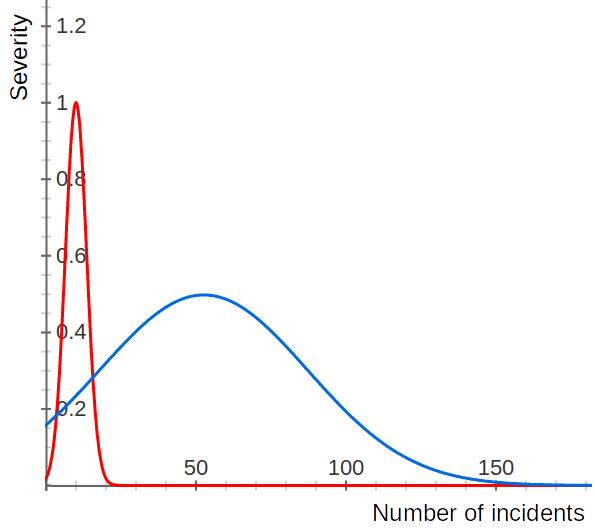
The blue curve represents incidents on a self-managed, decentralised infrastructure: mostly VPS and storage hosted at various providers in two geographical regions. Incidents were plenty and of every kind, especially human error, but also “unexplainable” infrastructure issues and data corruption. Incident severity kept us busy for longer than we would have liked but never overwhelmed us.
The red curve represents incidents on a public cloud provider in a single geographical region. The incidents recorded in a year were few and easy to work around (actually so easy that the ops team often didn’t record them), but a few, notable incidents caused a complete standstill of all production stages and severely impeded developing and testing stages.
Comparing the two curves we see that running on self-managed infrastructure kept us busy with all kinds of little annoyances and it took constant effort to not let those annoyances grow into problems. Most of that pain went away after migrating to the public cloud, at the cost of few, crippling outages we could not work around.
Epilogue
The time my team spent on dealing with self-managed infrastructure is directly translated into operational cost that doesn’t scale, even though the infrastructure diversity (which contributed to cost) made sure we never had a complete outage. By moving operations to the cloud we offloaded significant work to the cloud provider which reduced the number of “every day” incidents, but we also lost control over essential parts of our incident mitigation strategy which led to a few severe outages. The bottom line calculation still shows that the public cloud was the way to go, but if top-percentile availability is a major business factor, then a multi-cloud or hybrid cloud architecture is a one-way street.
