I’m experimenting with protecting the perfect NAS RAID setup against bit rot (silent data corruption in long storage) and recently experimented with dm-integrity towards that end. The idea is to add checksums on the block level to each hard disk so that data corruption shows up as an I/O error to md, which would then repair the failing block with redundant information from other disks.
The target setup looks like this in theory:
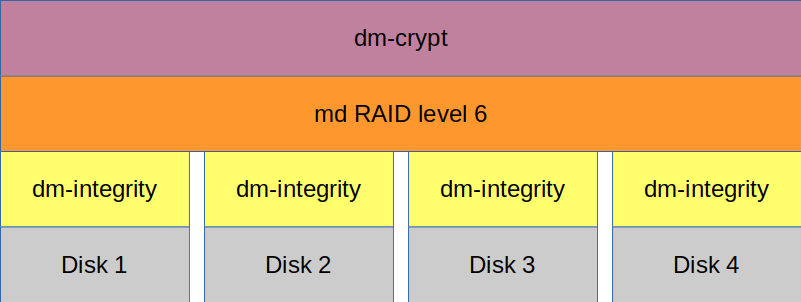
The four lowest boxes (Disk 1 – Disk 4) are four identical partitions on four hard disks. dm-integrity then sets up block devices on top of those hard disks which contain checksums for each block. Data corruption in a block (eg. on Disk 1) would be identified by the dm-integrity block device and reported to higher levels as a bad block. Md (the large orange box above dm-integrity) is used to set up a level 6 RAID (lower levels will work, too) which distributes redundant data across the four dm-integrity block devices. Data corruption on a disk would be detected by the overlaying dm-integrity device which would report that as a bad block to md. Md would then recompute the correct data from the other disks and overwrite the bad block with the correct data. dm-crypt is (the purple box on top) just my own paranoia and doesn’t add anything to data integrity.
My original setup is similar to the one shown above, just without the dm-integrity layers. I planned to migrate my integrity-less RAID 6 to one with integrity, so I failed and removed the first disk, converted it to an dm-integrity device and added that to the RAID. The resync took about 12 hours (a full resync usually takes 10 hours) with moderate CPU load (sorry, I forgot the number). Replacing the second disk with a dm-integrity device however was so slow (ETA for resync was about 4 days) that I stopped the experiment and reverted to the previous setup.
I asked a question about this on stackexchange but haven’t received any input so far.
Update & errata
The kernel module “md” had been erroneously referred to as “dm-raid”.

Hi George! I noticed that your SO question still doesn’t have an answer. Did you manage to find a solution yourself?
LikeLike
It wasn’t meant to be. In the mean time I switched to snapraid (post upcoming) for the bulk of my archive and an encrypted RAID for everything else.
LikeLike